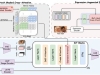
从静态图像生成富有表现力的面部动画是一项具有挑战性的任务。以往依赖显式几何先验(如人脸关键点或三维形状模型 3DMM)的方法,在跨身份迁移时容易产生伪影,且难以捕捉细腻的情感。此外,现有方法普遍不支持多角色动画生成,因为来自不同角色的驱动特征往往会相互干扰,进一步加大任务的复杂度。为了解决这些问题,阿里巴巴提出了FantasyPortrait,一个基于扩散变换器的框架,能够在单角色和多角色场景中生成高保真、情感丰富的面部动画。 在多角色控制方面,FantasyPortrait 设计了掩码式交叉注意机制,实现各角色表情生成的独立性与协调性,有效避免特征干扰。为了推动该领域的研究,作者还构建了两个专门用于训练和评估多角色人像动画的新数据集与评测基准:Multi-Expr和ExprBench。需要注意的是,扩散模型依赖的迭代采样过程会导致生成速度较慢,这可能限制其在实时应用中的广泛使用。 01 技术原理 FantasyPortrait 的整体架构如图所示。给定一张参考人像图像和一个包含面部动作的视频片段,系统首先从视频序列中提取隐式的面部表情特征,然后将这些特征迁移并融合到目标人像中,生成最终的面部动画视频输出。
提出了一种新颖的增强表达隐式控制方法(expression-augmented implicit control method),该方法旨在从隐式面部表示中学习细粒度的表情特征,同时显著提升对复杂面部动态(尤其是嘴部动作和情感表达)的建模能力。此外,还设计了一种多角色掩码式交叉注意机制(multi-portrait Masked Cross-Attention mechanism),以实现多个角色之间表情的精确且协调的控制。 多角色人像动画:FantasyPortrait 支持使用多个单人视频或一个包含多人的视频来驱动多个角色,生成细腻的表情与真实感十足的人像动画。 多样化角色风格:FantasyPortrait 能够为不同风格的角色生成动画,输出动态、生动且自然逼真的风格化视频。 动物动画:尽管未在动物数据集上进行过专门训练,FantasyPortrait 依然展现出出色的动物动画生成能力,具备很强的泛化性。 音频驱动的人像动画:可以轻松地将视频驱动的人像动画模型扩展为音频驱动的人像动画框架。具体来说,使用 Whisper 对音频进行编码,并通过一个小型的基于 Transformer 的网络将音频特征映射到潜在的驱动表示中。 值得注意的是,与其他基于 DiT 的音频驱动方法相比,FantasyPortrait 仅需数千条训练样本就能实现出色的音频与视觉对齐效果。更重要的是,现有主流方法和数据集主要集中在英语场景,若要适配其他语言,通常需要高昂的数据采集成本和计算开销。而FantasyPortrait方法只需几百条样本、以及大约 1 小时的 GPU 微调时间,即可支持新的语言或方言,大幅降低了使用门槛,促进了技术的普惠性。 欢迎交流~,带你学习AI,了解AI |